这个很多人都做过,文章也挺多的,我也是参考别人文章的,不过直到真正实现还是踩了许多坑,所以记录下来,或许对其他人有帮助。其实LLVM和Clang我还没有好好研究过,之前大部分都是用Swift开发,代码风格检查都是用的Swiftlint,所以这次选择OC的代码检查作为开始,通过实践找找感觉和兴趣,之后再一点一点精进。
[llvm cookbook] 模块化设计示例
llvm被设计成一系列库的集合。什么意思?就是每个模块都可以拿出来单独使用。
本文用llvm优化器opt命令行工具来展示它的模块化用法。
编写文件 testfile.ll
define i32 @test1(i32 %A) { |
[llvm cookbook] IR优化
本文介绍如何使用opt工具优化llvm ir。
使用之前编写的代码 multiply.c
int mult() { |
执行命令
clang -emit-llvm -S multiply.c -o multiply.ll |
生成 multiply.ll
; ModuleID = 'multiply.c' |
执行命令:
opt -mem2reg -S multiply.ll -o multiply1.ll |
输出 multiply1.ll
; ModuleID = 'multiply.ll' |
DWARF详解
DWARF 是一种调试信息格式,通常用于源码级别调试
相关资料比较琐碎, 整理给大家, 希望大家可以用得上
如没有特殊说明, 命令执行环境为 OS X
什么是 DWARF ?
- DWARF 第一版发布于 1992 年,主要是为UNIX下的调试器提供必要的调试信息,例如PC地址对应的文件名及行号等信息,以方便源码级调试
- 其包含足够的信息以供调试器完成特定的一些功能, 例如显示当前栈帧(Stack Frame)下的局部变量, 尝试修改一些变量, 直接跳到函数末尾等
- 有足够的可扩展性,可为多种语言提供调试信息: 如: Ada, C, C++, Fortran, Java, Objective C, Go, Python, Haskell …
- 除了编译/调试器外,还可用于从运行时地址还原源码对应的符号|行号的工具(如: atos)
Obfuscation-llvm混淆flatten源码分析
1. Control Flow Flattening算法

源码层面的control flow flattening

源码层面的控制流图
图(a)为原始代码,图(b)为经过control flow flattening的代码,图(c)为原始代码的控制流图,图(d)为经过control flow flattening的代码的控制流图。[1]
LLVM的指令映射机制分析
[C++实现]遍历LLVM字节码文件的所有Instruction
LLVM提供的工具已经十分丰富,基本上可以满足我们的使用需求,但是使用现成的工具往往会具有一定的局限在性,遇到问题是,我们总是喜欢自己撸代码来完成自己的目标,那么如何编译LLVM字节码文件中的Instruction呢? 且看下面的源代码:
#include <fstream> |
LLVM测试框架
LLVM测试框架简介
在LLVM编译器后端开发过程中,针对特定平台必然要定义特定指令集及其指令格式,并对后端流程的各个阶段或pass做相应修改。根据需求编写“测试用例”的测试驱动开发(Test-DrivenDevelopment,简称TDD)是推动开发进行的有效方法,可以在出现问题时实现可回溯,有助于编写简洁可用和高质量的代码。LLVM测试框架是在LLVM编译器后端开发过程中实现测试驱动开发的有效手段,有很高的灵活性和健壮性,可保证加速开发过程稳步进行。
本文涵盖LLVM测试框架,需要用到的工具,以及如何增加和运行测试用例。LLVM测试框架主要包括两类:回归测试和整体程序测试。回归测试代码位于LLVM代码库llvm/test路径下。这些用例应在每次提交前运行通过。整体程序测试也称为LLVM测试套件(LLVM test suite)。
剖析LLVM寄存器分配(2)- 贪厌寄存器分配器工作原理和过程
在前文《LLVM后端流程简介》中提到,和指令选择、指令调度一样,寄存器分配是编译器后端的一个重要组成部分,寄存器分配在后端流程中的位置如下图所示。
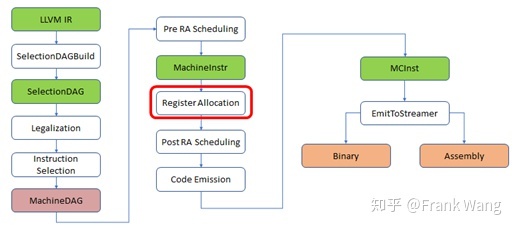
LLVM3.0之前的缺省寄存器分配器是线性扫描分配器,LLVM3.0之后新增了基本(basic)分配器和贪厌(greedy)分配器,而贪厌分配器是LLVM新的缺省分配器。和线性扫描分配器相比,贪厌分配器用一个优先级队列取代线性扫描分配器的活跃列表(actvie list),并按优先级访问队列中的生命期,而不是像线性扫描分配器那样按先后顺序访问。贪厌分配器的另一个改进是在生命期溢出前增加一个切分步骤,这样可以增加生命期被分配到物理寄存器的可能性。
LLVM后端流程简介
Program Work Flow
如果我们要编译opencl/cuda代码,并已经有了一些opencl/cuda kernel,以及在主机端运行的代码。主机端代码调用kernel。如下图所示:
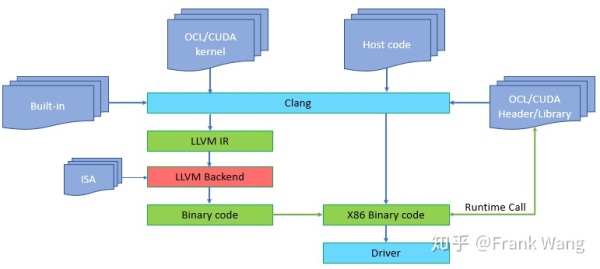
在主机端,执行clang编译主机代码,这和正常编译类似,但是要链接opencl/cuda runtime。对kernel代码, 也会执行clang编译kernel 代码,生成LLVM IR。为了支持kernel built-in function,这里使用built-in lib,比如对opencl,一般使用的built-in lib是libclc。
主机代码调用runtime api,比如opencl的clCreateProgramWithBinary,生成kernel。主机端代码也可以调用其它runtime call来为相应设备创建comandQueue,或者得到设备或平台信息。