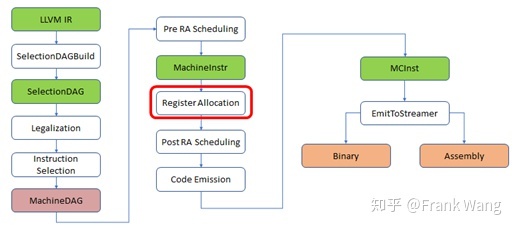
在前文《LLVM后端流程简介》中提到,和指令选择、指令调度一样,寄存器分配是编译器后端的一个重要组成部分,寄存器分配在后端流程中的位置如下图所示。
LLVM3.0之前的缺省寄存器分配器是线性扫描分配器,LLVM3.0之后新增了基本(basic)分配器和贪厌(greedy)分配器,而贪厌分配器是LLVM新的缺省分配器。和线性扫描分配器相比,贪厌分配器用一个优先级队列取代线性扫描分配器的活跃列表(actvie list),并按优先级访问队列中的生命期,而不是像线性扫描分配器那样按先后顺序访问。贪厌分配器的另一个改进是在生命期溢出前增加一个切分步骤,这样可以增加生命期被分配到物理寄存器的可能性。
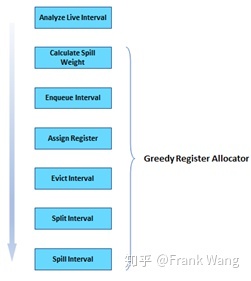
在寄存器分配之前,需要做很多准备工作,例如指令序号标记、活跃分析等。LLVM中的活跃分析主要分为两个部分:活跃变量分析(live variable analysis,在LiveVariables类中实现)和生命期分析(live interval analysis,在LiveInterval类中实现)。这些都是在分配器之外的其它pass中完成。如果将分配器选择进一步细分,可以分成切分权重计算(Split weight calculation)、生命期入队列(Enqueue)、指定物理寄存器(Assignment)、剔除(Eviction)、切分(Splitting)和溢出(Spilling)等阶段,如下图所示:
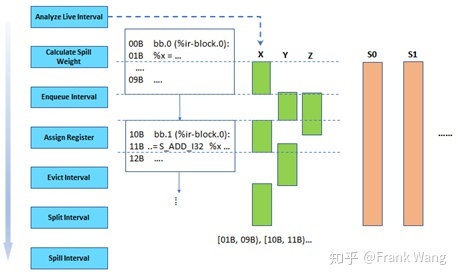
生命期分析是一个standalone pass。在此之前,SlotIndexes pass已经为每条指令标记序号。通过检查变量的uses 和defs,可以分析生命期。因为此时每一条指令都已经有序号,可以将分析得到的生命期用一个片段集合表示。例如下图中,变量x的定义在基本块0的指令序号01B处,基本块0在指令序号09B处结束,可得到x的第一段生命期为[01B,09B)。x在基本块1的指令序号11B处被使用,因此x的第二段生命期为[11B,11B)。同理可得其它生命期分析结果。
在LLVM的LiveInterval类定义了寄存器(或值)的生命期,以及部分寄存器分配器状态。LiveInterval类的定义在include/llvm/CodeGen/LiveInterval.h文件中,代码如下:
class LiveInterval : public LiveRange { |
生命期分析的入口函数在LiveIntervals.cpp的runOnMachineFunction(),代码如下:
bool LiveIntervals::runOnMachineFunction(MachineFunction &fn) { |
成员变量VirtRegIntervals定义如下,其中包含了为所有虚拟寄存器计算得到的生命期。
IndexedMap<LiveInterval*, VirtReg2IndexFunctor> VirtRegIntervals; |

生命期分析主要调用三个方法:computeVirtRegs()、computeRegMasks()和computeLiveInRegUnits()。computeVirtRegs()代码如下。该方法会遍历每一个虚拟寄存器,并以虚拟寄存器为参数,调用方法createAndComputeVirtRegInterval(),基于uses和defs为虚拟寄存器计算生命期。
void LiveIntervals::computeVirtRegs() { |
createAndComputeVirtRegInterval()先调用createEmptyInterval()为每个虚拟寄存器生成一个空的LiveInterval,保存在VirtRegIntervals[Reg]中。如果是虚拟寄存器,LiveInterval的weight初始值为0;如果是物理寄存器,LiveInterval的weight初始值为huge_valf,即无穷大。然后,以LiveInterval为参数调用computeVirtRegInterval()方法。
LiveInterval &createAndComputeVirtRegInterval(unsigned Reg) { |
computeVirtRegInterval()方法进一步调用:
LRCalc->reset(MF, getSlotIndexes(), DomTree, &getVNInfoAllocator()); |
生命期分析的另一个主要方法是computeLiveInRegUnits()。
得到生命期分析结果后,接下来就是贪厌分配器pass。贪厌分配器第一个阶段是根据各个生命期的特点计算相应的溢出权重(spill weight)。对溢出权重影响最大的是变量使用密度(use density)。例如在for循环中的变量会被频繁使用,使用密度较大。这类变量尽量不要被溢出到内存中,否则严重影响程序效率。因此对这类变量要提升权重,即weight *= 3。
其它影响权重的因素还包括:
是否可重物质化(rematerializable),对于这类生命期,可以作为溢出的候选,因为不指定给物理寄存器影响不大,值可以重新计算得到,因此,将其对应权重减半,即
totalWeight *= 0.5F;是否为hinted寄存器。在特定目标架构中,某些指令会有偏好的寄存器,这些寄存器称为hinted寄存器。对于这类寄存器,对其权重会做些微提升即
totalWeight *= 1.01F。
溢出权重计算过程代码在lib/CodeGen/CalcSpillWeights.cpp文件中的calculateSpillWeightsAndHints()方法中实现。该方法会被各寄存器分配器在初始化后调用。
在计算得到所有生命期的溢出权重后,应该根据生命期特点将所有生命期放入优先级队列中(如下图所示),由优先级队列决定各个生命期分配寄存器的顺序。某个生命期的优先级并不等同于溢出权重。比如,局部变量的优先级比全局变量低,因为贪厌分配器优先分配长的生命期,但短生命期也有较大概率填充进长生命期留下的寄存器使用空隙。
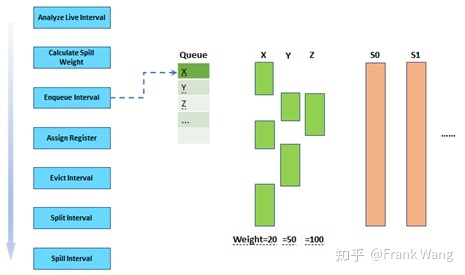
队列中的每一个生命期都要经历随后的四个阶段,即:指定寄存器、剔除、切分和溢出。如上图所示,比如目标架构有两个物理寄存器S0和S1,并且在优先级队列中有三个生命期x、y、z。第一个生命期x有最高优先级,可以分配到寄存器S0。同理,可以将y分配到寄存器S1。当给z分配寄存器时会发现z和S0中的x,以及S1中的y都有干扰(interference),如下图所示。因此不能将z直接分配到S0或S1。
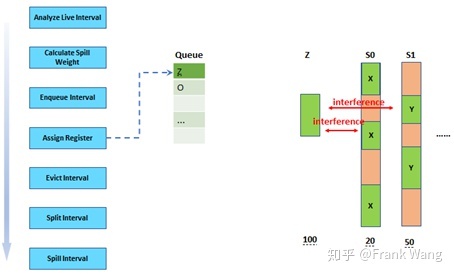
为了解决这个问题,贪厌分配器会将z的溢出权重和已经被分配到寄存器中的x和y(与z存在干扰的生命期)的溢出权重作比较,找出溢出权重较小的生命期,并将其从寄存器中剔除(evict)。在这个例子中,x的溢出权重(20)较小,因此将其从S0中剔除。相应的,z被指定到寄存器S0。被剔除的生命期仍进入优先级队列,等待再次分配寄存器。
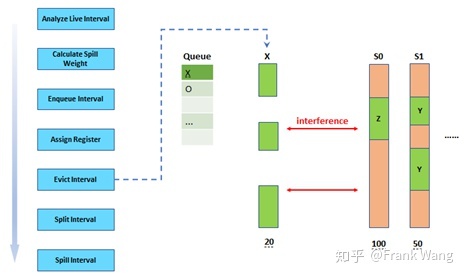
当再次从优先级队列中取出生命期x,准备为其分配寄存器时,x仍然与S0中z和S1中的y存在干扰。而且因为x的溢出权重最小,无法将y或z从已分配寄存器中剔除。这时,贪厌分配器将x标记为x*,表示可以被切分(但此时并未真正切分)。标记后的x*仍被放回优先级队列,但其优先级被降低,所以位于队列中其它生命期之后,如下图所示。

当优先级队列中其它生命期都被处理完后,最后处理x*。这时才会对x*做切分。当切分时,会根据需要产生新的生命期,以及相应的copy指令。例如,为了切分x*,产生2个新的生命期x1和x2,原有的生命期x*将被弃用,而只为x1和x2分配寄存器。
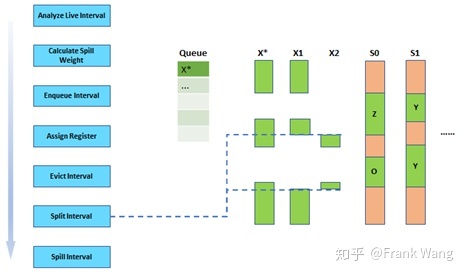
新的生命期x1和x2仍需根据各自特点计算溢出权重,并进入优先级队列,如下图所示。为x1和x2分配寄存器的流程与前述处理类似。因此,被剔除的生命期可以获得第二次机会分配寄存器。如果切分后的生命期,因为和其它生命期存在干扰,仍然无法被分配到寄存器,则最终被溢出,如下图所示。切分和剔除操作使得贪厌分配器能以一种渐进的方式优化寄存器分配。在程序计算密集区域的生命期可以剔除溢出权重较低的生命期并分配到寄存器。这样优化的结果是大部分生命期可以被指定到寄存器,只有一些短的生命期会溢出,因此,留给rewrite的工作量也就很小,因为需要清理的东西很少。
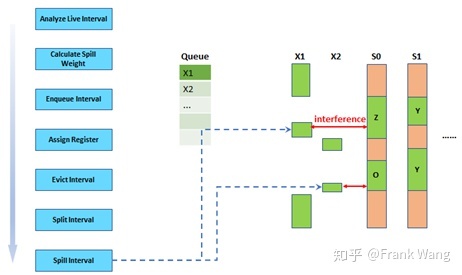
在长生命期太多的情况下,可能留给短生命期的空隙不够用,而有些短生命期可能很重要,具有较大的溢出权重,将其溢出到内存代价较高。这时,可以将已经指定寄存器,但溢出权重较小的长生命期剔除出寄存器,放进优先级队列等待重新分配。如果这个长生命期在下一次分配时找不到更小的溢出权重的生命期可以剔除,也不会立即被溢出,而是可以切分成更小的生命期,放进优先级队列等待重新分配。这是贪厌分配器的一个重要优化。
长生命期在程序运行期的很长时间内可能都是空闲的,只是在某些特定时间段内,如for循环内被频繁使用。这种情况下,可以给循环内的生命期赋予较大溢出权重,保证其能被分配到寄存器中。而对于其它空闲时间段内的生命期可溢出到内存。
示例如下图所示。生命期x的溢出权重比y的溢出权重小,且都希望分配到寄存器S0。但x有一部分运行在for循环中。
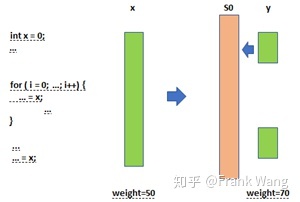
因为x具有较高的优先级(长生命期),因而先于y被分配到寄存器,造成和y的干扰,继而导致y不能不被分配到寄存器,如下图所示。
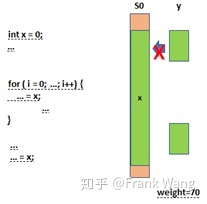
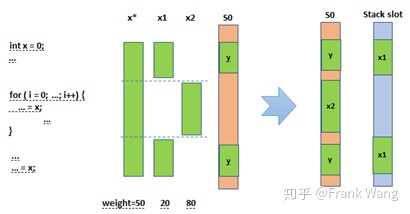
因为x的溢出权重小于y,x会被从S0中剔除,y将被分配到S0。而x经过上述过程将被切分。切分阶段会考虑x在特定时间段的for循环内被频繁使用,因此给循环内的生命期x2赋予较大溢出权重(80),而对于其它空闲时间段内的生命期x1赋予较小溢出权重(20)。如此便可保证x2能被分配到寄存器中,而对于x1可溢出到内存。过程如下图所示:
作者: 汪岩
来源: zhuanlan.zhihu.com/p/56409890