Program Work Flow
如果我们要编译opencl/cuda代码,并已经有了一些opencl/cuda kernel,以及在主机端运行的代码。主机端代码调用kernel。如下图所示:
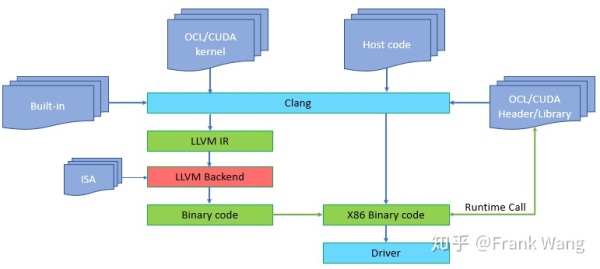
在主机端,执行clang编译主机代码,这和正常编译类似,但是要链接opencl/cuda runtime。对kernel代码, 也会执行clang编译kernel 代码,生成LLVM IR。为了支持kernel built-in function,这里使用built-in lib,比如对opencl,一般使用的built-in lib是libclc。
主机代码调用runtime api,比如opencl的clCreateProgramWithBinary,生成kernel。主机端代码也可以调用其它runtime call来为相应设备创建comandQueue,或者得到设备或平台信息。
Pipeline
LLVM backend的主要功能是code gen,也就是代码生成,其中包括若干个code gen分析换转化pass将LLVM IR转换成特定目标架构的机器代码。当然我们希望这个机器 代码是最优化的机器代码。LLVM backend具有流水线结构,如下图所示。指令经过各个阶段,从LLVM IR到SelectionDAG,再到MachineDAG,再到MachineInstr,最后到MCInst。有些资料中不将MachineDAG不做为单独的一种指令格式,因为其基本格式仍然是SelectionDAG,只不过其中的指令是目标相关指令。这其中经过的各个阶段实际是不同的pass,包括Instruction selection(指令选择)、Register allocation(寄存器分配),instruction scheduling已经code emission。不同的target的backend根据需要对不同pass做customization。
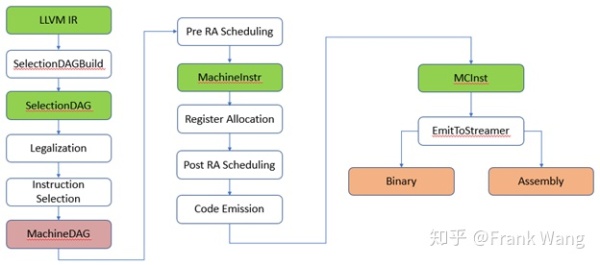
下面来具体看看每个pass和步骤的功能。
首先,SelectionDAGBuilder遍历LLVM IR中的每一个function以及function中的每一个basic block,将其中的指令转成SDNode,整个function或basic block转成SelectionDAG。这时DAG中每个node的内容仍是LLVM IR 指令。
SelectionDAG经过legalization和其它optimizations,DAG节点被映射到目标指令。这个映射过程是指令选择。这时的DAG中的LLVM IR节点转换成了目标架构节点,也就是将LLVM IR 指令转换成了机器 指令.所以这时候的DAG又称为machineDAG。
在machineDAG已经是机器 指令,可以用来执行basic block中的运算。所以可以在machineDAG上做instruction scheduling确定basic block中指令的执行顺序。指令调度分为寄存器分配前的指令调度,和寄存器分配后的指令调度。寄存器分配前的指令调度器实际有2个,作用于SelectionDAG,发射线性序列指令。主要考虑指令级的平行性。经过这个scheduling后的指令转换成了MachineInstr三地址表示。指令调度器有三种类型:list scheduling algo, fast algo, vliew.
寄存器分配为virtual Register分配physical Register并优化Register分配过成使溢出最小化。
virtual Register到physical Register的映射有2中方式:直接映射和间接映射。直接映射利用TargetRegisterInfo和MachineOperand类获取load/store指令插入位置,以及从内容去除和存入的值。间接映射利用VirtRegMap类处理load/store指令。寄存器分配算法有4种:Basic Register Allocator、Fast Register Allocator、PBQP Register Allocato、Greedy Register Allocator。
寄存器分配后的指令调度器作用于机器指令,也就是MachineInstr。这时能得到physical寄存器信息,可以结合physical Register的安全性和执行效率,对指令顺序做调整。
Code emission阶段将机器 指令转成MCInstr,并发射汇编或二进制代码。
Initial Selection Construction
SelectionDAG类用一个DAG表示一个basic block。SelectionDAG的创建是个基本的窥孔算法。LLVM IR经过SelectionDAGBuilder的处理后转换成SelectionDAG。下图是c代码实现除法,只有一个function,一个basic block。
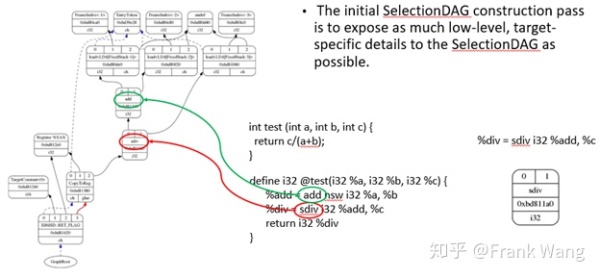
IR经过多个优化pass做进一步优化后由SelectionDAGBuilder类产生Selection DAG节点。当SelectionDAGBuilder遇到IR指令,调用相应的visit()方法,比如,如果是sdiv操作,就调用visitSDiv()方法将两个操作数保存到SDValue,从DAG中得到一个SDNode节点并以ISD::SDIV作为其操作符。在该IR中,操作数0为%add,操作数1为%c。其它计算也做类似处理。处理完所有IR指令后,IR被转为如图所示的SelectionDAG。每一个DAG表示一个基本块中的计算,不同的基本块与不同的DAG关联。节点表示计算,边有不同含义。将IR转化为DAG很重要,因为这可以让代码生成器使用基于树的模式匹配指令选择算法。此时的SelectionDAG还与目标设备无关,但对于具体目标设备来说,有些指令可能不合法,因为不同目标设备支持的指令集不同,指令集中的指令与IR指令可能没有对应关系。例如,x86不支持sdiv而支持sdivrem。
下面详细介绍DAG图中不同符号的含义。DAG中的每个节点SDNode会维护一个记录,其中记录了本节点对其它节点的各种依赖关系,这些依赖关系可能是数据依赖(本节点使用了被其它节点定义的值),也可能是控制流依赖(本节点的指令必须在其它节点的指令执行后才能执行,或称为chain)。这种依赖关系通过SDValue对象表示,对象中封装了指向关联节点的指针和被影响结果的序列号。也可以说,DAG中的操作顺序通过DAG边的use-def关系确定。如果图中的sdiv节点有一个输出的边连到add节点,这意味着add节点定义define了一个值,这个值会被sdiv节点使用。因此,add操作必须在sdiv节点之前执行。
- 黑色箭头表示数据流依赖。数据流依赖表示当前节点依赖前一节点的结果。
- 虚线蓝色箭头表示非数据流链依赖。链依赖防止副作用节点,确定两个不相关指令的顺序。比如,load和store指令如果访问相同的内存位置,就必须和他们在原程序中的顺序保持一致。从图中的蓝色箭头可知,copytoreg操作必须在ret_flag之前发生,因为他们之间是链依赖。
- 红色箭头表示glue依赖。Glue是用来防止两个指令在scheduling时分开,即他们中间不能插入其它指令。
每个节点的类型,可以是实际的数据类型,如i32,i64等,也可以是chain类型,表示chain values,或者是glue类型,表示glue。
SelectionDAG对象有一个特殊的EntryToken来标记basic block的入口。EntryToken的类型是ch,允许被链接的节点以这个第一个token作为起始。
在这张图中,目标无关和目标相关的节点共存。Copyfromreg、copytoreg、add等是目标无关节点。Register %EAX、TargetConstant是和ret_flag是目标相关节点。
- CopyFromReg:copy当前basic block外的register,用在当前环境,这里用于copy函数参数。
- CopyToReg:copy一个值给特定寄存器而不提供任何实际值给其它节点消费。然而,这个节点产生一个chain value被其它节点链接,这些其它节点不产生实际值。比如为了使用写到EAX的值,ret_flag节点使用EAX寄存器提供的i32结果,并消费CopyToReg节点产生的chain,这样保证EAX随着CopyToReg更新,因为chain会使得CopyToReg在ret_flag之前被调度。
Legalization
从SelectionDAGBuilder输出的SelectionDAG还不能做指令选择,在SelectionDAG机制从DAG节点产生机器指令之前,DAG节点还要经过几个转化阶段,其中合法化是最重要的阶段,如下图所示。做合法化的原因是SelectionDAGBuilder构造的SDNode中的指令操作数类型和操作不一定能被目标平台支持。
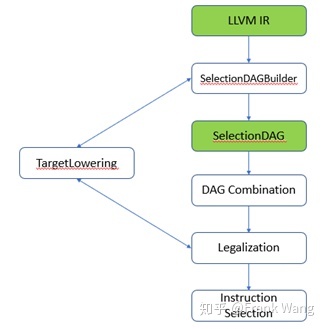
SDNode的合法化涉及类型和操作的合法化。首先介绍操作的合法化。
目标平台一般不可能为所有支持的数据提供IR中所具有的全部指令,x86上没有条件赋值(conditional moves)指令,PowerPC也不支持从一个16-bit的内存上以符号扩展的方式读取整数。因此,合法化 阶段要将这些不支持的指令按三种方式转换成平台支持的操作:扩展(Expansion) ,用一组操作来模拟一条操作; 提升(promotion)将数据转换成更大的类型来支持操作; 定制(Custom),通过目标平台相关的Hook实现合法化。
下图以x86除法指令为例说明操作的合法化。LLVM IR的sdiv只计算商,而x86除法指令计算得到商和余数,分别保存在两个寄存器中。因为指令选择会区分SDIVREM和sdiv,因此当目标平台不支持SDIV时需要在合法化阶段将sdiv扩展到sdivrem指令。
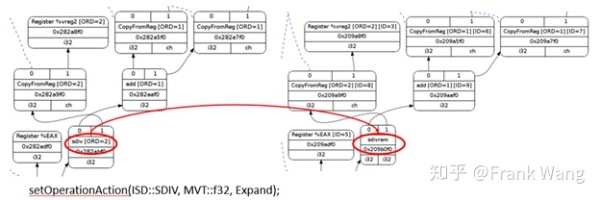
目标平台相关的信息通过TargetLowering接口传递给SelectionDAG。目标设备会实现这个接口以描述如何将LLVM IR指令用合法的SelectionDAG操作实现。在x86的TargetLowering构造函数中会通过”expanded”这个label来标识。当SelectionDAGLegalize::LegalizeOp看到SDIV节点的Expand标志会用SDIVREM替换。类似的,目标平台相关的合并方法会识别一组节点组合的模式,并决定是否合并某些节点组合以提高指令选择质量。
类型合法化pass保证后续的指令选择只需要处理合法数据类型。合法数据类型是目标平台原生支持的数据类型,例如,目标平台的td文件中会定义每一种数据类型关联的寄存器类。例如,
def FPRegs : RegisterClass<"SP", [f32], 32, (sequence "F%u", 0,31)>; |
这里定义了一组32个从F0-F31 单精度浮点类型的寄存器。
def DFPRegs : RegisterClass<"SP", [f64], 64, (add D0, D1, D2, D3, D4, D5, D6, D7, D8, D9, D10, D11, D12, D13, D14, D15)>; |
定义了一组16个从D0-D5 双精度浮点类型的寄存器。
如果平台的td文件的寄存器类定义没有相应的数据类型,那对平台来说就是非法数据类型。非法的类型必须被删除或做相应处理。根据非法数据类型不同,处理方式分为两种情况。第一种是标量。标量可以被promoted(将较小的类型转成较大的类型,比如平台只支持i32,那么i1/i8/i16都要提升到i32),expanded(将较大的类型拆分成多个小的类型,如果目标只支持i32,加法的i64操作数就是非法的。这种情况下,类型合法化通过integer expansion将一个i64操作数分解成2个i32操作数,并产生相应的节点);第二种是矢量。LLVM IR中有目标平台无法支持的矢量,LLVM也会有两种转换方案, 加宽(widening),即将大vector拆分成多个可以被平台支持的小vector,不足一个vector的部分补齐成一个vector;以及标量化(scalarizing),即在不支持SIMD指令的平台上,将矢量拆成多个标量进行运算。
目标平台也可以实现自己的类型合法化方法。类型合法化方法会运行两次,一次是在第一次DAG combine之后,另一次是在矢量合法化之后。无论怎样,最终都要保证转换后的指令与原始的IR在行为上完全一致。
在做合法化时,还有其它可能的情况要考虑。比如,某种目标平台寄存器类支持某种向量类型,但某个特定的操作不支持这个向量类型。举个例子,x86支持v4i32类型,但没有x86指令支持v4i32类型的ISD::OR操作,只支持v2i64。这样,向量合法化pass就要promote使用v2i64类型。
DAG Combine pass是将一组节点用更简单结构的节点代替。比如一组节点表示(add(Register X), (constant 0))将寄存器X中的值和常数0相加,这种情况可以简化成(Register X),和常数0相加无效,被优化掉了。
setTargetDAGCombine() 方法表示哪些节点可以被组合,例如:
setTargetDAGCombine(ISD::ADD); |
Combine pass在legalization后执行,可以最小化SelectionDAG的冗余节点。
Instruction Lowering
SelectionDAG中已经有和目标相关的节点。为什么会这样?为了理解这个问题,首先看图1。这里面包括了Instruction selection之前的所有步骤,以LLVM IR起始。首先,SelectionDAGBuilder遍历LLVM IR中的每一个basic block,生成SelectionDAG。在这个过程中,某些指令,如call和ret已经需要目标相关信息。比如如何传递调用参数,如何从函数返回。
为了解决这个问题,TargetLowering类中的算法会在这里被首次使用。不同目标的backend要实现TargetLowering抽象接口。只有一小部分节点会在这里转成目标相关节点,大部分节点都在instruction selection中在pattern match后被替换成机器指令。
Instruction selection
指令选择是backend中的一个重要阶段。从耗时方面来说,指令选择占用了backend总耗时的一半。指令选择通过节点模式匹配完成DAG到DAG的转换,将SelectionDAG节点转换成表示目标指令的节点。这一阶段的输入是经过合法化的SelectionDAG,如下图所示。
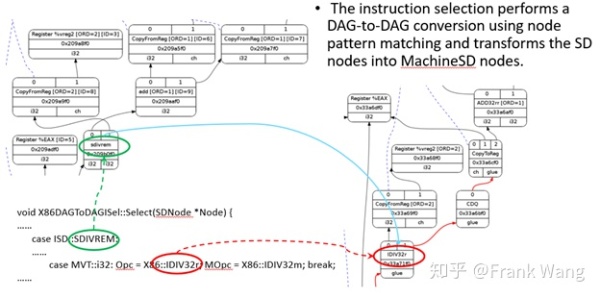
LLVM的指令选择需要tablegen辅助来产生一种基于表的指令选择机制。目标平台的backend可以在SelectionDAGISel::Select方法中实现定制代码手工处理某些指令。其它指令通过SelectCode由默认的指令选择过程处理。例如在x86 backend中,对于经过合法化的SDIVREM操作就是手动方法做指令选择的。Select方法的输入SDNode节点如果是SDIVREM,会选择对应的x86指令opcode,也就是IDIV32r,并生成一个MachineSD节点。MachineSD节点是SDNode的子集,其中的内容是平台机器指令,但仍然以DAG node的形式表示。其中CopyToReg,CopyFromReg和Register节点在寄存器分配阶段之前保持不变。有三种类型的指令表达会在同一个DAG中共存:一般LLVM ISD节点,如ISD::ADD,平台相关ISD节点,如X86ISD::RET_FLAG,和平台指令,如X86::ADD32ri8.
在Select方法最后会调用Selectcode方法,如下图所示。这个方法是tablegen为目标平台生成的。主要的作用就是将ISD和平台ISD映射到机器指令节点。这种映射通过Matcher table实现。

Instruction scheduling
指令选择完成后的MachineDAG内容虽然是机器指令,但仍然是以DAG形式存在,CPU/GPU不能执行DAG,只能执行指令的线性序列。寄存器分配前的指令调度的目的就是通过给DAG节点指定执行顺序将DAG线性化。最简单的办法就是将DAG按拓扑结构排序,但LLVM backend用更智能的方法调度指令使其运行效率更高。
调度器会调用InstrEmitter::EmitMachineNode发射一系列指令到MachineBasicBlock,指令的形式是MachineInstr(MI),DAG表示形式不再使用,可以销毁。指令调度会根据性能需要做优化,特别是考虑寄存器footprint。

Register Allocation
经过指令选择阶段产生的代码是SSA形式的,即静态单赋值。这些代码假定可以使用无限多的虚拟寄存器。这当然是不可能的。因此接下来要执行寄存器分配,将无限的虚拟寄存器替换成有限的物理寄存器。如果物理寄存器数量不够用,虚拟寄存器就会被assing到内存,也就是spill slot。但也有例外,比如在x86的除法指令中,输入要保存在EDX和EAX寄存器中。指令选择阶段就已经知道这个限制,因此在那个时候,也就是select方法中就会为除法指令分配物理寄存器而不必等到寄存器分配阶段。
寄存器分配过程依赖几个pass的分析结果,包括Register coalescer和virtual register rewrite,如下图所示。Coalescer的目的主要是消除冗余的copy指令,在RegisterCoalescer类中实现,这是一个machine function pass。Machine function pass是按function为单位作用在机器指令而不是IR指令上。在coalescing时,joinAllIntervals方法遍历copy操作列表,joinCopy方法从copy机器指令中生成Coalescerpair,并将copy合并。

Interval是程序的一对起点和终点。从起点开始,某个值被产生并在被某个临时位置持有,一直到这个值被使用和销毁。下面分析在bc程序上运行coalescer情况,如下图所示。

其中的序号0B,16B…是每条MI的序号,也称为slot index,每个序号对应一个live range slot。字母B对应Block,用于live range的进入/离开一个basic block的边界。在这个例子中,index都带B,因为这是默认的slot。不同的slot,字母r,会出现在interval中,表示寄存器,用于标号一个普通的寄存器use/def slot。
从示例中的指令可以看出,%vreg0,%vreg1,%vreg2,%vreg3是需要分配物理寄存器的虚拟寄存器。因此在这段代码中会用掉4个物理寄存器,另外还有两个&I0和&I1。这两个是已经使用的物理寄存器,因为有遵守ABI调用规则。需要这些物理寄存器传递函数参数。
在coalescing之前会运行活动变量(live variable)分析pass,因此实例代码中会有活动变量信息,显式每个寄存器在哪个时刻被定义和销毁。***
INTERVALS **之后的信息就是活动变量分析结果,** MACHINEINSTRS **之后的信息是机器指令。活动变量信息对我们分析寄存器的相互影响很有用,如果在同一时间有几个虚拟寄存器存活,就需要分配不同的物理寄存器。
前面提到,coalescing只是寻找寄存器copy。在寄存器到寄存器的copy中,coalescer会尝试将源寄存器的interval和目的寄存器的interval连起来,使源和目的寄存器公用一个物理寄存器,这样就可以减少一个copy指令,16B-32B就是这种情况。Coalescer需要知道每个虚拟寄存器存活的interval以便知道应该将哪些interval合并。例如,从示例中可以看到,虚拟寄存器%vreg0的interval是[32r:48r:0)。这表示%vreg0在32定义,在64被销毁。48后的0是一个代码,表示第一次定义这个interval的地方。0的含义在0@32r中表示,说明0就在32r,其实我们已经知道这个含义了。但如果interval在后面被分裂了,这个定义可以用来跟踪interval的原始定义。
从示例中的interval可以发现,%I0的interval是[0B, 32r :0],%vreg0的interval是[32r , 48r : 0]。在32处有一个copy指令将%I0 copy到%vreg0。这是就可以做coalesce,将[0B, 32r : 0] [32r , 48r :0]这两个interval合并,并为%I0和%vreg0分配同一个物理寄存器,过程如下图所示。但遗憾的是,物理寄存器(例如%I0)的interval必须被保留,也就是物理寄存器不能被分配到其它的live range存活范围。所以coalescer会放弃这个机会,因为担心将%I0分配给整个range可能会对整体运行性能有影响,所以让后续的寄存器分配阶段来决定。
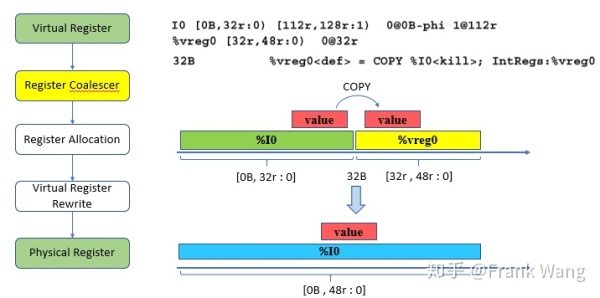
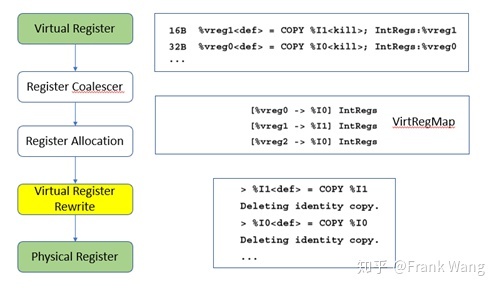
寄存器分配pass为每个虚拟寄存器分配物理寄存器后,VirtRegMap会保存寄存器分配结果,实际是一张从虚拟到物理寄存器的映射表,如下图所示。接下来,虚拟寄存器rewrite pass会根据映射表将指令中的虚拟寄存器替换成物理寄存器,并删除相同寄存器之间的copy操作。所以,coalesce不能删除的copy指令,寄存器分配可以通过给两段live range分配相同的物理寄存器,将冗余copy操作删除。
调用约定
调用约定定义描述了怎样向函数传值,以及如何从函数返回值。参数传递方式和目标平台高度相关。td格式文件中定义的调用约定由一系列条件和预定义action组成。为了支持平台特定的调用约定,在<target>CallingConv.td定义了目标平台返回值调用约定和基本C调用约定,文件中使用CCIfType和CCAssignToReg等接口指定:
- 函数参数分配顺序
- 函数参数和返回值是放在寄存器中还是放在stack
- 使用哪个寄存器
- caller或callee是否对栈回溯
从下图的例子可以看出CCIfType和CCAssignToReg接口的用法。如果CCIfType预测为真,也就是说,如果当前参数类型是f32或i32,就会执行CCAssignToReg这个动作action,也就是将参数值赋值给I0-I5的第一个可用寄存器。

其中,RetCC_Sparc32指明了对某种标量返回类型应该用哪个寄存器。例如,单精度浮点返回到F0,双精度浮点返回到D0,32位整型返回到I0/I1。CC_Sparc32还用到了CCAssignToStack,这个action会以指定的大小和对齐方式将值赋给stack slot。在这个例子中,第一个参数4表示slot的大小为4byte,第二个参数4表示stack是4字节对齐。如果参数为0,则沿用ABI中的定义。
函数参数会首先尝试放入I0-I5中的可用寄存器。如果I0-I5全都被之前的函数调用占用,就会采用stack model的调用约定。将函数参数值放入一个4字节大小、4字节对齐的slot。
还有一种比较常用的接口是CCDelegateTo,该接口用于查找特定的子调用约定。例子中,当前函数参数值赋值给ST0/1后,就会执行RetCC_X86Common。CCDelegateTo经过tblgen处理后会变成函数调用。CCIfCC接口用于将参数1中给定的名称与当前调用约定匹配。如果参数1的名称与当前调用约定相同,参数2指定的action会被执行。例子中,如果正在使用Fast CallingConv(”CallingConv::Fast”),RetCC_X86_32_Fast这个action就会被执行。
def RetCC_X86_32_C : CallingConv<[ |
Code emission
在介绍code emission之前首先介绍MC framework。MC framework的主要作用是对function和指令做底层处理。和其它后端模块相比,MC framework设计的目的是用来辅助产生基于LLVM的汇编器和反汇编器。之前的NVPTX backend没有集成的汇编器,编译过程只能进行到发射PTX为止,产生PTX作为输出,然后依赖外部工具,比如PTXAS完成其余的编译步骤,如Register allocation和code emission。在code emission的早期阶段会用机器码指令(MCInstr)取代机器指令(MachineInstr)。和MI相比,MCInst携带的程序信息较少。
Code emission阶段发生在所有post-register allocation之后。Code emission在asmprinter这个pass中开始。下图是从MI指令到MCInstr,再到汇编或二进制指令要经过的步骤:
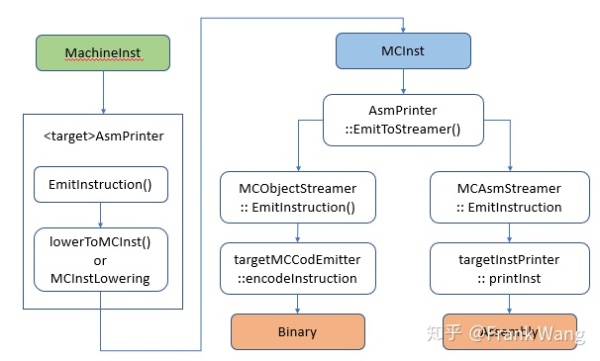
AsmPrinter是一个machine function pass.
AsmPrinter首先发射function header,然后遍历所有基本块,一次分发一条MI指令到EmitInstruction()方法做后续处理。自定义backend都会提供一个AsmPrinter子类重载这个方法。
目标设备的EmitInstruction()收到MI指令输入后通过MCInstLowering interface将其转换为MCInst instance。自定义backend会提供MCInstLowering接口子类,并由其中的定制代码产生MCInst实例。
此时有两个选项:发射汇编或二进制指令。MCStreamer类处理MCInst指令流,通过两种类MCAsmStreamer和MCObjectStreamer将其发射到选定的输出。MCAsmStreamer子类将MCInst转换为汇编指令,MCObjectStreamer子类将MCInst转换为二进制指令。
如果生成汇编代码,MCAsmStreamer::EmitInstruction()被调用,并使用自定义backend提供的MCInstPrinter subclass将汇编指令打印到文件中。
如果生成二进制指令,MCObjectStreamer::EmitInstruction()被调用LLVM object code assembler,并使用自定义backend提供的MCCod
作者: 汪岩
来源: zhuanlan.zhihu.com/p/52724656